Spark 学习日记(初探)
历史
hadoop 1.x
HDFS:用 NameNode 管理 DataNode。 Map-Reduce:用 JobTracker 管理(调度) TaskTracker
hadoop 1.x Map-Reduce 的缺点
Map-Reduce 是基于数据集的计算,是面向数据的。
- 基本的运算规则从介质中获取,计算后再存储到介质中。所以主要应用于一次性计算。在当前的大数据环境中是无法接受的。不适合数据挖掘和机器学习这样的迭代计算。
- 基于文件,
IO效率慢。 - 和
hadoop紧密耦合,无法替换。
hadoop 2.x Yarn 的出现
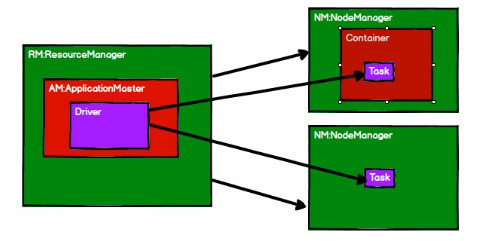
RM(ResourceManager)
NM(NodeManager)
AM(ApplicationMaster)
RM -> NM -> Container -> Task
RM -> AM -> Driver -> Task
Spark 的出现是为了改善 hadoop 1.x 的不足
基于内存,使用 Scala 语言,适合迭代计算
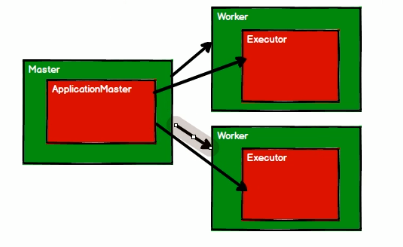
HDFS + Yarn + Spark
Spark 模块
- Spark Core
- Spark SQL
- Spark Streaming
- Spark MLib
- Spark GraphX
SBT 管理 jar 包依赖
可以使用下面的方式来定义一个依赖,其中 groupId,artifactId 和 revision 都是字符串:
ini
libraryDependencies += groupId % artifactId % revision使用国内镜像加速:
创建修改 ~/.sbt/repositories 加入阿里的镜像
ini
[repositories]
local
aliyun: https://maven.aliyun.com/repository/publicSpark 统计单词数量
新建一个 sbt 项目
sbt:
ini
name := "spark"
version := "0.1"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.6"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.4.6"input:
ini
Hello World
Hello Scala
Hello SparkSparkWordCount:
scala
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main(args: Array[String]) {
val logFile = "input" // Should be some file on your system
val conf = new SparkConf()
conf.setAppName("SparkWordCount") // 设置应用名称
conf.setMaster("local[1]") // 设置本地模式,1个进程
val sc = new SparkContext(conf)
val data = sc.textFile(logFile, 2).cache()
val words = data.flatMap(_.split(" "))
val wordOnce = words.map((_, 1))
val wordWithCountList = wordOnce.reduceByKey((a, b) => a + b)
wordWithCountList.foreach(println)
sc.stop()
}
}输出:
ini
(Hello,3)
(World,1)
(Scala,1)
(Spark,1)Spark 和 Yarn 联合使用
在 spark 目录中修改 spark-env.sh
添加 YARN_CONF_DIR=/xxx/hadoop/etc/hadoop